Multi-threshold Neuron Model
This post was originally published in the GoDataDriven blog
Inspired by a new biological scientific research, I propose, build and train a Deep Neural Network using a novel neuron model.
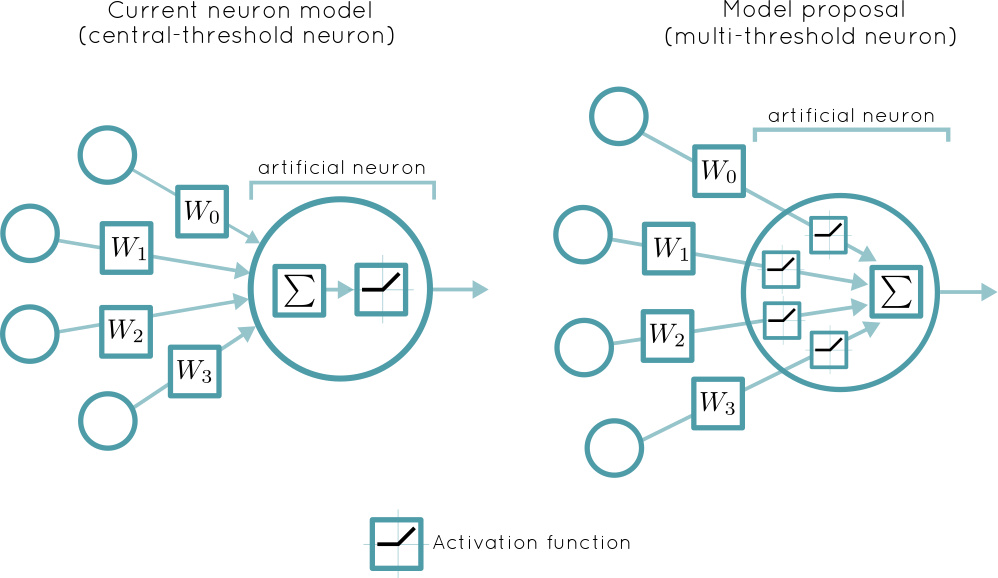
Figure 0. Schematic diagrams of two neuron models. (Central-threshold neuron) The model on the left is the current employed model in artificial neural networks where the input signals are propagated if their sum is above a certain threshold. (Multi-threshold neuron) In contrast, in the right I show the new proposed model where each input signal goes through a threshold filter before summing them.
In this blog post I construct and train a simple Deep Neural Network based on a novel experimental driven neuron model proposed last year (2017) in July. This blog is separated as follows:
- Scientific background
- Summarize the article that lead me to this idea and explain some of the theory.
- Concepts
- Relate Deep Learning technical concepts to Neuroscience concepts mentioned in the paper.
- Approximations
- Introduce approximations I will make on the multi-threshold neuron model.
- Discussion
- Overview of mathematical and Deep Learning implications as a consequence of the multi-threshold neuron model.
- Model & training
- Tensorflow implementation and training of a simple fully-connected Deep Neural Network using the multi-threshold neuron model.
- Results
- Briefly show and explain results from training and testing the proposed model vs the commonly used one in Deep Neural Networks (DNNs).
Scientific background

S. Sardi et al. published in July last year (2017) an experimental work in Nature scientific reports which contradicts a century old assumption about how neurons work. The work was a combined effort between the Physics, Life Sciences and Neuroscience departments of Bar-Ilan University in Tel Aviv, Israel.
The authors proposed three different neuron models which they put to the test with different types of experiments. They describe each neuron model with, what they call, neuronal equations.
Below I describe two of these neuron models in the paper. In particular the commonly used neuron model which I call "central-threshold" and the neuron model proposal in this blog "multi-threshold".
Central-threshold neuron
This is the current adopted computational description of neurons (artificial neurons), and the corner stone of Deep Learning. "A neuron consists of a unique centralized excitable mechanism". The signal reaching the neuron consists of a linear sum of the incoming signals from all the dendrites connected to the neuron, if this sum reaches a threshold, a spike signal is propagated through the axon to the other connected neurons.
The neuronal equation of this model is:
$$I = \Theta\Big(\sum_{i=1}^NW_i\cdot I_i - t\Big)$$
where
- $i$: identifies any connected neuron
- $N$: total number of connected neurons
- $W_i$: is the weight (strength) associated to the connection with neuron $i$
- $I_i$: is the signal coming out of neuron $i$
- $t$: is the centralized single neuron threshold
- $\Theta$: is the Heaviside step function
- $I$: signal output from the neuron
Multi-threshold neuron
In this model the centralized threshold ($\Theta$) is removed. The neuron can be independently excited by any signal coming from a dendrite given that this signal is above a threshold. This model describes a multi-threshold neuron and the mathematical representation can be written as:
$$I=\sum_{i=1}^N\Theta(W_i\cdot I_i - t_i)$$
where
- $i$: identifies any connected neuron
- $N$: total number of connected neurons
- $W_i$: is the weight (strength) associated to the connection with neuron $i$
- $I_i$: is the signal coming out of neuron $i$
- $t_i$: is the threshold value for each neuron $i$
- $\Theta$: is the Heaviside step function
- $I$: signal output from the neuron
Study conclusion
Based on their experiments the authors conclude that the multi-threshold neuron model explains best the data. The authors mention that the main reason for adopting the central-threshold neuron as the main model, is that technology did not allow for direct excitation of single neurons, which other model experiments require. Moreover, they state that these results could have been discovered using technology that existed since the 1980s.
Concepts
There are some main concepts in the Deep Learning domain that you should be familiar with before proceeding. If you are familiar with them skip this part.
Artificial neuron
A mathematical representation of a biological neuron. They are the corner stone of artificial neural networks and Deep Learning. The idea is that the artificial neuron receives input signals from other connected artificial neurons and via a non-linear transmission function emits a signal itself.
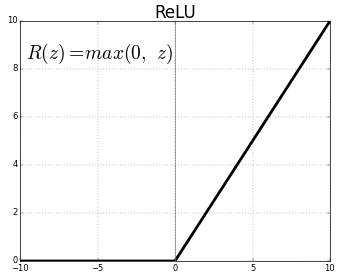
Activation function
The current understanding of a neuron is that it will transmit some signal only if the sum from incoming signals from other neurons exceeds a threshold. For an artificial neuron this threshold filter is applied via an activation function. There are many activation functions but the Rectified Linear unit (ReLu) is one of the most broadly used in the Deep Learning community, and it's the one I will use in this notebook. The mathematical definition of the function is:
$$R(z) = max(0, z) = \begin{cases} 0 &\quad\text{for } z\leq0 \ z &\quad\text{for } z > 0 \end{cases}$$
You can check its implementation in the Tensorflow source code or in the Tensorflow playground code.
Approximations

I am a theoretical physicist and as such it's impossible for me to resist the spherical cow.
Single threshold value
The multi-threshold neuron model contains different threshold parameter values ($t_i$). Mathematically a threshold has the same effect if I take it as a constant and instead the input signal is moved up or down by the connecting weight parameters. Hence, the neuronal equation becomes: 1
$$I=\sum_{i=1}^N\Theta(W_i\cdot I_i - t)$$
ReLu activation function
I'll replace the Heaviside step function ($\Theta$) with threshold $t$ by a Rectified Linear unit ($\mathcal{R}$).
$$I=\sum_{i=1}^N\mathcal{R}(W_i\cdot I_i)$$
In general any activation function could replace the Heaviside step function.
Bias
Notice that the proposed model equation contains no bias terms. I'll add a bias term to the equation since it's known to help neural networks fit better. It can also help with the threshold approximation, tuning the biases instead of the thresholds.
$$I=\sum_{i=1}^N\mathcal{R}(W_i\cdot I_i) + b$$
Discussion
The idea is to take the multi-threshold neuron model and try to write a Deep Learning implementation, a neural network consisting of multi-threshold neurons. Tensorflow is quite flexible and allows for writing user defined implementations.
Backpropagation
In order for my neural network to be trained I need backpropagation, this means that the derivative of whatever I introduce is necessary. Luckily, I'm not changing the activation function itself, I can just use the already derivative of the ReLu function in Tensorflow:
$$\frac{d}{dz}\mathcal{R}(z)= \begin{cases} 0 &\quad\text{for } z\leq0 \ 1 &\quad\text{for } z > 0 \end{cases}$$
You can check it out in the Tensorflow source code or in the Tensorflow playground code.
Tensor multiplication
What I'm really changing is the architecture of the artificial neural network as seen in Figure 0, the activation function is no longer applied on the sum of all the inputs from the connected neurons, but instead on the input arriving from every single connected neuron. The sum operation is going from inside the activation function to outside of it:
$$\mathcal{R}\Big(\sum_{i=1}^NW_i\cdot I_i\Big) \rightarrow \sum_{i=1}^N\mathcal{R}(W_i\cdot I_i)$$
Do you see the implementation problem described by the equation above?
In the central-threshold model (left equation) the input to the activation function $\sum_iW_i\cdot I_i$ is exactly the dot product between vectors $(W_1, W_2,\dots,W_N)$ and $(I_1, I_2,\dots,I_N)$ and it's this fact which allows fast computation of input signals for many neurons and observations at once via a single matrix multiplication.
In the multi-threshold model this is no longer possible. I think this will be the biggest challenge when coming up with an implementation which can be trained efficiently and fast.
Example
Suppose I have the following weight matrix connecting two neuron layers, the first layer has 3 neurons the second has 2:
$$W= \begin{bmatrix} 3 & -4 \ -2& 2\ 0& 4 \end{bmatrix} $$
and that the output signal from the neurons in the first layer are
$$I_0= \begin{bmatrix} 2 & 5 & 1 \end{bmatrix} $$
with bias terms
$$b= \begin{bmatrix} 2 & -1 \end{bmatrix} $$
Using the standard central-threshold neuron model, the output signal of the second layer is:
$$\mathcal{R}\Big(I_0\cdot W + b\Big) = \mathcal{R}\Big( \begin{bmatrix} 2 & 5 & 1 \end{bmatrix} \cdot \begin{bmatrix} 3 & -4 \ -2& 2\ 0& 4 \end{bmatrix} + \begin{bmatrix} 2 & -1 \end{bmatrix} \Big) = $$ $$ \mathcal{R}\Big( \begin{bmatrix} -2 & 5 \end{bmatrix} \Big) = \begin{bmatrix} \mathcal{R}(-2)& \mathcal{R}(5) \end{bmatrix} \Big) = \begin{bmatrix} 0 & 5 \end{bmatrix} $$
In the case of the multi-threshold neuron model proposed the output is
$$ [\sum_{i=1}^N\mathcal{R}(W_{i1}\cdot I_i) + b_1, \sum_{i=1}^N\mathcal{R}(W_{i2}\cdot I_i) + b_2]= $$ $$ \begin{bmatrix} \mathcal{R}(6) + \mathcal{R}(-10) + \mathcal{R}(0) + 2 & \mathcal{R}(-8) + \mathcal{R}(10) + \mathcal{R}(4) -1 \end{bmatrix} = \begin{bmatrix} 8 & 13 \end{bmatrix} $$
As the example shows, a fundamental difference is that in the multi-threshold case if any input output signal times the weight is positive then the output will be positive. This will greatly reduce the sparsity of the neurons firing throughout the network in comparison with the conventional central-threshold model.
I don't know all the implications but I expect that it will be more difficult for individual neurons (or parts of the network) to singly address a specific feature, therefore in principle reducing overfitting.
A known issue of most activation functions in Deep Neural Networks is the "vanishing gradient problem", it relates to the decreasing update value to the weights as the errors propagate through the network via backpropagation. In the standard central-threshold model the ReLu partially solves this problem by having a derivative equal to 1 if the neuron fires, this propagates the error without vanishing the gradient. On the other hand, if the neuron signal is negative and squashed by the ReLu (did not fire) the corresponding weights are not updated, since the ReLu derivate is zero i.e. neuron connections are not learning when the connecting neurons didn't fire. In the multi-threshold model, I expect this last issue to be reduced since sparsity reduces, more weights should be updated on each step in comparison with the central-threshold neuron.
Model & training
I first concentrate in replicating the example above using tensorflow, it contains two built-in related ReLu functions:
relu_layerrelu
The relu_layer function already assumes a layer architecture with central-threshold neurons. The relu function on the other hand can operate on each entry of a tensor.
import tensorflow as tf
sess = tf.Session()
b = tf.constant([2, -1])
w = tf.constant([[3, -2, 0], [-4, 2, 4]])
I_0 = tf.constant([2, 5, 1])
I_1 = tf.reduce_sum(tf.nn.relu(tf.multiply(I_0, w)), axis=1) + b
I_1.eval(session=sess)
>>> array([ 8, 13], dtype=int32)
Notice that b and I_0 are one dimensional tensors, this allows me to take advantage of the tensorflow broadcasting feature. Using the code above I can then define a neural network layer consisting of multi-threshold neurons2.
def multi_threshold_neuron_layer(input_values, weights, b, activation=tf.nn.relu):
return tf.reduce_sum(activation(tf.multiply(input_values, weights)), axis=1) + b
MNIST - 2 hidden layer multi-threshold neural network
With this basic implementation, my goal was to see if the model is actually trainable. I just wanted to observe the loss decrease with each iteration. As you probably noticed, the multi_threshold_neuron_layer can only take 1 example at a time, this is the complication I mentioned, simple matrix multiplication taking several observations is no longer possible for now. In part II of the blog I hope to expand to a more efficient implementation.
The multi-threshold neural network is then:
# Construct model
I_0 = tf.placeholder("float", shape=(input_size,)) # input layer
W_01 = tf.Variable(tf.random_normal((hidden_layers_sizes[0], input_size)))
b_1 = tf.Variable(tf.random_normal((hidden_layers_sizes[0],)))
I_1 = multi_threshold_neuron_layer(I_0, W_01, b_1) # 1st hidden layer
W_12 = tf.Variable(tf.random_normal((hidden_layers_sizes[1], hidden_layers_sizes[0])))
b_2 = tf.Variable(tf.random_normal((hidden_layers_sizes[1],)))
I_2 = multi_threshold_neuron_layer(I_1, W_12, b_2) # 2nd hidden layer
W_23 = tf.Variable(tf.random_normal((number_of_classes, hidden_layers_sizes[1])))
b_3 = tf.Variable(tf.random_normal((number_of_classes,)))
output = tf.transpose(tf.matmul(W_23, tf.reshape(I_2, shape=(-1, 1)))) + b_3 # output layer
# truth
target = tf.placeholder("float", shape=(1, number_of_classes))
Using the digits MNIST data set I ran a comparison between a DNN using the conventional central-threshold neurons and the proposed multi-threshold neurons.3
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp", one_hot=True)
Results
It is trainable! I actually though this would just crash and burn so I was very happy to see that loss go down :).
I calculated the cross-entropy loss and accuracy during training and final accuracy in a test set. It is very important to remember that to keep things fair the calculations for both models are using a batch of 1 observation.
The training period ran for 4 epochs with a training set of 55000 observations. Normally the loss and accuracy is calculated over the batch, in this case that makes no sense4. Instead what I do is report the average loss and average accuracy over every 1100 observations 5.
The score of my model consisted of calculating the accuracy over a test set of 10000 observations.
Training loss and accuracy
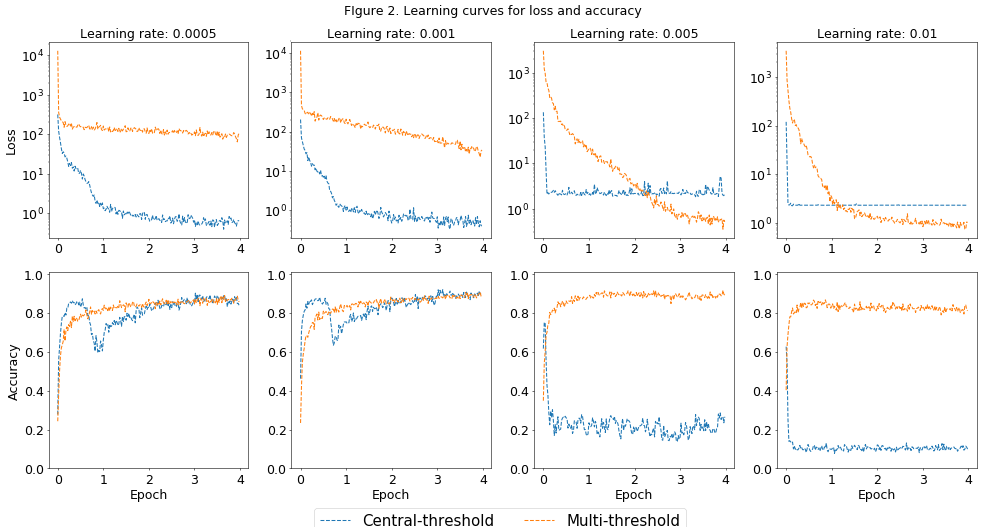
There are many things that can be discussed from Figure 2 but here are the main points:
- Cross-entropy loss decreases with iterations which means the model is trainable.
- When the
central-thresholdmodel is performing well its loss is much lower than themulti-threshold. Notice that this is the case since the beginning of the training period, a sort of a shift. This could be because our images contain consistent white areas (edges) where the cross-entropy benefits from having sparse activations in our neural network. - The
multi-thresholdmodel seems to be more robust against higher learning rates. Moreover, it seems to prefer higher learning rates. - As I mentioned before I would expect the
multi-thresholdmodel to have less sparse activations which in turn should result in a faster learning 6. This can be observed for learning rate.0005and.001.
Test Accuracy
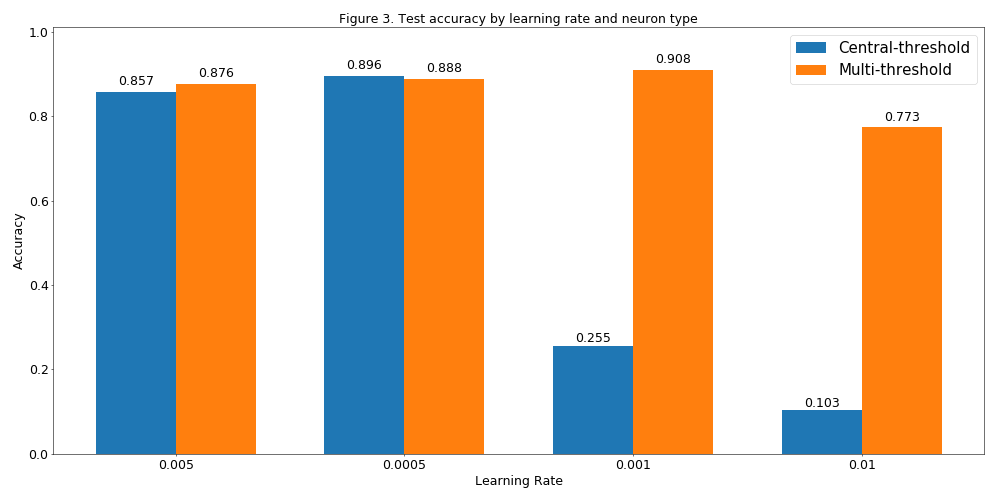
| Learning rate | Central-threshold | Multi-threshold |
|---|---|---|
| 0.0005 | 0.8571 | 0.8757 |
| 0.001 | 0.8958 | 0.8879 |
| 0.005 | 0.2554 | 0.9085 |
| 0.01 | 0.1028 | 0.773 |
- As seen in the training report above, the
multi-thresholdmodel seems to be more robust against higher learning rates. It could be that this is just a sort of shift and for even bigger learning rates it will show the same behavior as thecentral-threshold. - The
multi-thresholdmodel does not overfit in these examples. Even more, for learning rate 0.005 it achieves a loss 2 orders of magnitude higher than thecentral-thresholdbut a higher accuracy in the test set.
Adios
This was a pretty fun blog to make. I have some final remarks:
- The proposed model is trainable, but I cannot say much of the specifics since that requires more investigation that I have not done.
- A very important point is that since at the moment I can only use batches of 1, the training time is painfully slow, definitely not something for realistic applications.
- Finally, I know that Figure 3 seems quite promising but let's not forget that this is done with a batch of a single observation.
- In part II of this blog I'll try to come up with the functionality of having more observations per update and use a convolutional layer to make a more realistic comparison.

You can find the code here.
If you have any other questions just ping me in twitter @rragundez.
-
This is also happening in the current neural network implementations, since in reality there is no reason for different neurons to have the same threshold, nevertheless commonly a single activation function is used on all neurons. ↩
-
It is a one line function, I know I know, but I can already sense there will be more to it later since this just works for a single input example. ↩
-
Since at the moment the multi-threshold neuron model uses only a single example at a time, to make a fair comparison both DNN weights are updated on each example (batches of size 1),
x, y = mnist.train.next_batch(1, shuffle=True). ↩ -
If you do that the accuracy and loss will be all over the place as it will be dependent on a single observation. This could make difficult to assess if the model is indeed getting better on each iteration by seeing the loss monotonically decrease. ↩
-
You don't want this number to be too high since you expect an average lower loss and higher accuracy for observations at the end. If there are too many observations your standard deviation will increase and the reported average can be meaningless. ↩
-
The weights of a neural network using
reluactivations where the neuron output is zero cannot learn because the back-propagated derivative is zero. ↩